


MAIA – Monitoring AI for Intelligent Apiaries
Projektziele & Projektergebnis
Umsetzung projekt in den Bereichen „Prozesse“ mit dem Ziel der Erhöhung/Steigerung/ Optimierung der Produkt- / Servicequalität, des Innovationsgrades und von Prozessen.
Es ist grundsätzlich möglich, Milben mittels KI und einer Handykamera zu erkennen, doch besteht weiterer Optimierungsbedarf, um eine alltagstaugliche App zu entwickeln, die Imker*innen die Arbeit beim Auszählen der Milben erleichtern kann.
Gesamtprojekt
Top Erkenntnisse aus dem Projekt
Ausgangslage
Zentrale Fragestellungen im Projekt
- Eine besondere Herausforderung war, dass wir einen Kompromiss zwischen hoher Genauigkeit und kompakter Modellgröße finden mussten.
- Wie können wir machen, dass ein so kleines Objekt wie eine Varroa-Milbe zuverlässig erkannt wird?
- Wir haben uns gefragt, wie die einzelnen Augmentationsparameter Einfluss auf das Modellergebnis haben.
Projektdetails
Entwicklung eines KI-Modells zur visuellen Erkennung von Varroa destructor Milben in Bienenstöcken
Ausgangslage
Die Varroa destructor-Milbe zählt zu den größten Gefahren für Honigbienen weltweit. Sie schwächt einzelne Tiere durch das Aussaugen von Hämolymphe, überträgt Viren und kann bei starkem Befall ganze Bienenvölker zum Zusammenbruch bringen. Die Auswirkungen beschränken sich dabei nicht nur auf die Imkerei – auch Wildbienen geraten zunehmend unter Druck, da beispielsweise Viren wie das Flügel-Deformations-Virus sich über Blüten von Honigbienen auf Wildbienen übertragen können.
Um dem Befall frühzeitig entgegenzuwirken, ist eine regelmäßige Kontrolle durch die Imker notwendig. Die bisher übliche Methode besteht in der manuellen Zählung der Milben auf aus dem Volk entnommenen Proben, etwa nach einem Auswasch- oder Puderzuckerverfahren. Diese Vorgehensweise ist jedoch fehleranfällig, subjektiv in der Bewertung und mit erheblichem Zeitaufwand verbunden – insbesondere bei vielen Völkern oder in professionellen Imkereien.
Ziel dieses Projekts war es daher, ein leistungsfähiges Detektionsmodell auf Basis der YOLO-Architektur zu entwickeln, das Milben zuverlässig in hochaufgelösten Bildern identifiziert und quantifiziert. Diese Anwendung soll die Möglichkeit haben, leicht einsetzbar zu sein, beispielsweise in Form einer Handy App. Eine automatisierte, KI-gestützte Auswertung soll die Genauigkeit erhöhen, die Belastung für Imker senken und langfristig zur verbesserten Gesundheit von Bienenpopulationen beitragen.
Herausforderungen
Ein zentrales Ziel des Projekts bestand darin, ein KI-Modell zu entwickeln, das Objekte in Bildern zuverlässig erkennt und gleichzeitig auf mobilen Endgeräten wie Smartphones lauffähig ist. Daraus ergaben sich besondere Anforderungen an die Modellarchitektur.
Einerseits musste das Modell ausreichend klein und effizient sein, um auf Geräten mit begrenzter Rechenleistung – insbesondere mobilen Plattformen – performant eingesetzt werden zu können. Die Laufzeit und Speichernutzung sollten so gering wie möglich gehalten werden, um eine flüssige Anwendung ohne externe Serveranbindung zu ermöglichen.
Andererseits durfte die Reduktion der Modellgröße nicht zulasten der Erkennungsgenauigkeit gehen. Das Modell musste komplex genug bleiben, um die gesuchten Objekte in unterschiedlichen Umgebungen, Perspektiven und Beleuchtungssituationen zuverlässig zu erkennen. Es galt daher, einen sinnvollen Kompromiss zwischen Modellgröße, Performanz und Erkennungsqualität zu finden.
Ein weiterer wesentlicher Aspekt war der hohe zeitliche Aufwand für die Vorbereitung der Trainingsdaten. Damit das Modell präzise Vorhersagen treffen kann, ist es auf eine große Anzahl qualitativ hochwertig annotierter Bilder angewiesen. Die manuelle Annotation der Bilddaten – insbesondere das Markieren der relevanten Objekte mit Bounding Boxes oder Masken – stellte sich als sehr zeitintensiver und arbeitsaufwändiger Teil des Projekts heraus. Eine saubere Datenbasis war jedoch entscheidend für die spätere Modellleistung.
Vorgehen
Ein wesentlicher Bestandteil des Projekts war die Erstellung eines geeigneten Datensatzes zur Objekterkennung.
Zuerst wurde auf einen öffentlich verfügbaren Datensatz zurückgegriffen (https://doi.org/10.5061/dryad.kr07 , MIT-Lizenz). Diese wurden mit Hilfe von roboflow (roboflow.com) in Trainings-, Test- und Validierungsdaten unterteilt und durch gezielt systematisches Absuchen des Parameterraumes hingeblich der Augmentierungsdaten zum Trainieren des Modells verwendet. Dazu zählten zahlreiche Modifikationen wie Bildspiegelungen (Flip), Verzerrungen (Shear), Modifikation der Lichtwerte wie HUE, Sättigung, Helligkeit und weitere Störfaktoren wie Blurring und Noise, um die Robustheit und die Genauigkeit zu erhöhen. Dabei konnte im anschließenden Test der zur Verfügung stehenden APP von roboflow mit den Smartphones und im Labor nachgestellten Bedingungen (Milben auf einem Küchenpapier) leider kein Erfolg verzeichnet werden, da die zur Verfügung stehenden Daten mit den realen Bedingungen vermutlich zu stark divergierten.
Da keine weiteren öffentlich verfügbaren und ausreichend spezifischen Trainingsdaten für die automatische Erkennung von Varroa-Milben auf Bienenproben gefunden werden konnten, wurden die anschließenden Trainingsdaten vollständig selbst erzeugt. Hierzu wurden zunächst eigene Bildaufnahmen mit handelsüblichen Smartphones (Google Pixel 4A, IPhone 11) unter kontrollierten Bedingungen angefertigt. Insgesamt wurden 325 hochaufgelöste Bilder erstellt, die eine Vielzahl von realen Szenarien hinsichtlich Milbenanzahl, Bildausschnitt, Lichtverhältnissen und Hintergrund zeigen.
Die anschließende Annotation der Bilder stellte einen der zeitintensivsten Schritte im Projekt dar. Jede einzelne Milbe musste in den Aufnahmen manuell markiert und mit dem entsprechenden Label versehen werden, um dem Modell während des Trainings eindeutige Referenzen zu bieten. Diese Arbeit erforderte nicht nur Genauigkeit, sondern auch Fachwissen, um Milben sicher von Verunreinigungen oder Artefakten zu unterscheiden. Insgesamt stellte der Zeitaufwand für die Datenvorbereitung einen entscheidenden Faktor für die Projektdauer dar. Trotz des hohen Aufwands war eine saubere Datenbasis essenziell, um eine zuverlässige und robuste Objekterkennung zu ermöglichen.
Um die Trainingsdaten maximal auszuschöpfen und die Erkennungsgenauigkeit zu steigern, wurde ein mehrstufiger Ansatz zur Datenerweiterung verfolgt.
• Originalbilder: Ausgangsbasis waren 325 hochauflösende Aufnahmen von Bienenproben, aufgenommen unter kontrollierten Laborbedingungen.
• Tiling: Zur Erhöhung der Datenmenge wurden die Bilder in Overlapping-Tiles (z. B. 640×640 Pixel) zerlegt, was die Anzahl der Trainingsbeispiele auf über 1.500 Tiles erhöhte.
• Manuelle Annotation: Insgesamt wurden 7.500 Bounding-Box-Annotationen für Varroa-Milben von Expert:innen erstellt und hinsichtlich Konsistenz geprüft.
• Augmentation: Eine Kombination aus Photometrie- und Geometrie-Transformationen wurde angewandt, um Variationen in Beleuchtung und Position abzudecken:
o Zufällige Helligkeits- und Kontrastanpassung
o Rotationen bis ±20° sowie horizontale/vertikale Spiegelungen
o Gaussian Blur und Randabschneidungen für Fokusverschiebung
Zur Abwägung zwischen Performance und Genauigkeit wurden drei Varianten von YOLO11x (https://docs.ultralytics.com/de/models/yolo11/) konfiguriert und verglichen:
• YOLO11x Small hat eine reduzierte Layer-Anzahl und ist insbesondere für schnelle Inferenz bei eingeschränktem Speicherbedarf z.B. auf Mobilen Endgeräten oder Laptops ohne GPU.
• YOLO11x Medium ist ein Modell mit mittlerer Tiefe (Anzahl der Hiddenlayer) für robustere Erkennung kleiner Objekte.
• YOLO11x Large stellt das größte / tiefste Modell dar und hat die höchste Kapazität für höchste mAP-Werte, jedoch mit deutlich erhöhtem Rechenaufwand.
In dieser Phase wurde die Trainingspipeline mit besonderem Fokus auf Stabilität und reproduzierbare Ergebnisse implementiert, um ein gleichmäßiges und zuverlässiges Lernverhalten zu gewährleisten. Die folgenden Konfigurationsparameter bilden das Rückgrat des Trainingsprozesses:
• Epochen: 100 Trainingsepochen mit Early-Stopping nach 15 Epochen ohne Verbesserung.
• Batch-Größe: 2 aufgrund der hohen Bildauflösung (1920×1920).
• Bildgröße: Eingabe-Size von 640×640 bei Inferenz, intern auf 1920×1920 gecached.
• Lernrate: Initial 1e-3 mit Cosine Annealing Scheduler, Warmup-Phase 10 % der Gesamtepochen.
• Hardware: Training auf NVIDIA GPU (z. B. RTX 3090) mit 24 GB VRAM.
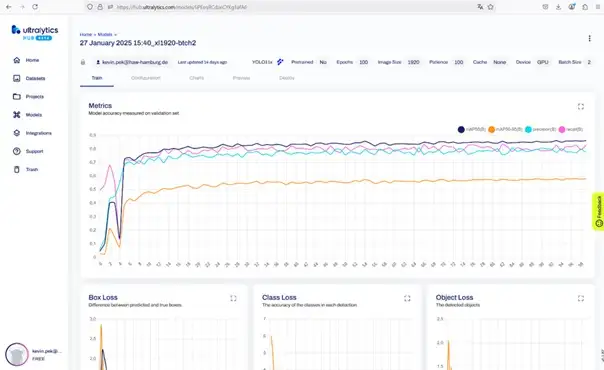
Nach Abschluss des Trainings wurden die Modelle anhand etablierter Metriken gründlich evaluiert, um Stärken und Schwächen in der Milbenerkennung zu identifizieren. Die Leistungsbewertung lief in zwei Schritten: Zunächst wurden quantitative Kennzahlen ermittelt, anschließend wurden die Ergebnisse qualitativ interpretiert.
Die folgenden mAP- und Performance-Werte geben Aufschluss über die Detektionsgenauigkeit:
• mAP@50 (B): 0,75–0,85 über alle Modellvarianten.
• mAP@50–95 (B): 0,45–0,55, wobei das Large-Modell den oberen Bereich erreichte.
• Precision: 0,75–0,85, abhängig von Schwellenwertanpassungen.
• Recall: 0,70–0,80, geringer bei sehr kleinen oder verdeckten Milben.
Insgesamt zeigen die Messwerte eine solide bis gute Erkennungsleistung, wobei mAP-Werte oberhalb von 0,8 bei moderater Komplexität als zufriedenstellend gelten und Verbesserungspotenzial insbesondere im Recall-Bereich bei kleinen Objekten besteht.
Um die Generalisierungsfähigkeit zu prüfen und Overfitting auszuschließen, wurde das Modell auf einem separaten Testdatensatz validiert:
• Testset-Performance: Konsistente mAP-Werte innerhalb von ±2 % zur Validierung.
• Robustheitstests: Bilder mit variierenden Lichtfarben (Tageslicht, Kunstlicht) belastet; die mAP sank um maximal 3 %.
• Fehleranalyse: Bei dicht gepackten Milben kommt es zu Bounding-Box-Überschneidungen, die Recall um bis zu 5 % senken.
Die Gradio-Benutzeroberfläche bietet eine intuitive und interaktive Möglichkeit, das Modell in Echtzeit zu testen und Parameter flexibel anzupassen:
• Modell-Auswahl: Über ein Dropdown-Menü können verschiedene .pt-Gewichtedateien ausgewählt werden, um schnell zwischen Trainingsergebnissen zu wechseln.
• Confidence-Threshold-Slider: Ein Schieberegler ermöglicht die dynamische Anpassung des Erkennungs-Schwellenwerts (0–1), um Falsch-Positiv- und Falsch-Negativ-Raten direkt im UI zu steuern.
• Sample-Bilder & Upload: Standardisierte Proben aus einem vordefinierten Ordner können geladen und eigene Bilder per Drag-and-Drop hochgeladen werden.
• Vorschau: Die rechte Seite zeigt sofort das Originalbild mit overlayten Bounding-Boxes und Konfidenzwerten nach jedem Modellaufruf.
• Interaktive Buttons: Reset- und Update-Buttons erlauben das schnelle Zurücksetzen oder Neuladen der aktuellen Konfiguration.
Die Abbildung unten demonstriert die App mit Modellauswahl, Threshold-Anpassung und Bildvorschau in Aktion
Erkenntnisse
Die erzielten Ergebnisse lassen sich wie folgt bewerten: Die Detektionsgenauigkeit liegt im oberen Mittelfeld vergleichbarer Studien, wodurch das Modell für praxisnahe Anwendungen geeignet ist. Einschränkungen zeigen sich jedoch bei sehr kleinen oder überlappenden Instanzen, was gezielte Verbesserungen im Bereich Augmentation und Modellarchitektur erfordert.
Zusammenfassend bietet das trainierte Modell eine solide Grundlage für eine automatisierte Milbenerkennung in Bienenproben. Für zukünftige Versionen empfehlen sich vortrainierte Backbones und erweiterte Augmentationsstrategien, um Recall und Robustheit weiter zu steigern.
Darüber hinaus sollte die Adaptierbarkeit auf Smartphones untersucht werden: Hierbei sind kompakte Modellgrößen und effizientes Quantisieren entscheidend, um die begrenzte Rechenleistung und Speicherressourcen mobiler Geräte optimal zu nutzen. Gleichzeitig müssen Aufnahmen mit variabler Bildqualität – abhängig von Kameraauflösung und Lichtbedingungen – durch adaptive Vorverarbeitungs-Pipelines (z. B. automatisches Zuschneiden und Normalisieren) zuverlässig gehandhabt werden. Für eine flüssige Inferenzphase sind spezielle Frameworks wie ONNX Runtime Mobile empfehlenswert, die Latenzzeiten auf unter 200 ms pro Inferenz halten können und so eine Echtzeitnutzung auf Endgeräten ermöglichen.
Darüber hinaus bietet die Ultralytics HUB App (https://docs.ultralytics.com/hub/app/) eine nahtlose Mobile-Integration: Mit der iOS- und Android-Anwendung lassen sich Ultralytics YOLO-Modelle (YOLOv5, YOLOv8 und YOLO11) direkt auf dem Smartphone ausführen. Die App nutzt Hardwarebeschleunigung durch Apple's Neural Engine (ANE) auf iOS sowie Android GPU und NNAPI-Delegates für erstklassige Echtzeit-Performance.
