Aus unsortierten Daten schnell und einfach Informationen
Projektziele & Projektergebnis
Erstellung projekt in den Bereichen „IT“ mit dem Ziel der Erhöhung/Steigerung/ Optimierung der Produkt- / Servicequalität und des Innovationsgrades.
Überprüfung der Machbarkeit von automatisierter Verarbeitung von PDFs, sowie die Erarbeitung und der Test verschiedener Lösungsansätze
Gesamtprojekt
Top Erkenntnisse aus dem Projekt
Ausgangslage
Zentrale Fragestellungen im Projekt
- Wie können PDFs automatisiert ausgelesen werden?
- Wie werden unsortierte Daten sinnvoll zugeordnet?
- Welche Tools können bei der Automatisierung unterstützen?
Projektdetails
Texte schreiben oder Bilder gestalten – Künstliche Intelligenz greift schon jetzt ganz lebenspraktisch unter die Arme. Large Language Models (LLMs) erleichtern den Zugang zu komplexen Daten und unterstützen Unternehmen bei Routine-Tätigkeiten. Zwei Aspekte, mit denen sich das Bildungs-Start-up Beyond Education nun gemeinsam mit dem Mittelstand-Digital Zentrum Schleswig-Holstein auseinandergesetzt hat.
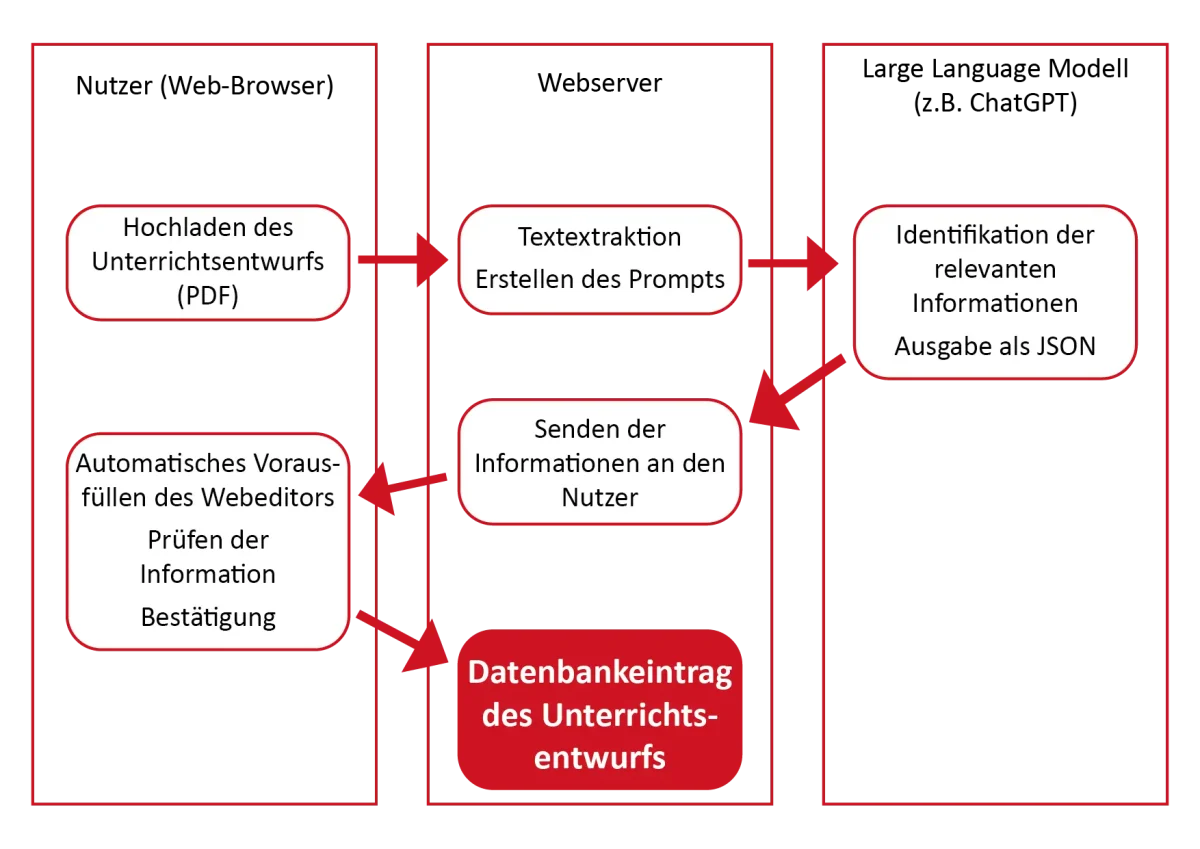
Gemeinsam mit Christoph Linse vom Zentrum Schleswig-Holstein entwickelte das Start-up einen zweischrittigen Lösungsansatz, bei dem ChatGPT als LLM den Nutzenden die Routinearbeit abnimmt. Es findet wichtige Informationen in den Texten und setzt sie in vorgefertigte Formulare ein. Beyond Education hat sich gemeinsam mit Christoph Linse damit beschäftigt, wie PDFs ausgelesen und dann mithilfe eines LLMs sinnvoll verarbeitet werden können. Die Herausforderung dabei: Viele Unterrichtsentwürfe enthalten Tabellen oder Grafiken, die ein sinnvolles Auslesen erschweren. Eine automatisierte Lösung muss daher besonders in diesem Bereich gute Ergebnisse liefern. Dadurch, dass Mittelstand-Digital anbieterneutral arbeitet, konnten verschiedene Varianten und Softwarelösungen ausprobiert werden, wodurch Beyond Education die für sich passende Lösung finden konnte.
.jpg-1024x683.webp)